
2024年9月現在、ChatGPTやClaude、Gemini等どのLLMモデルにも会話履歴を保持する機能があり、前の会話を参照して回答を上手く生成することができます。例えば、
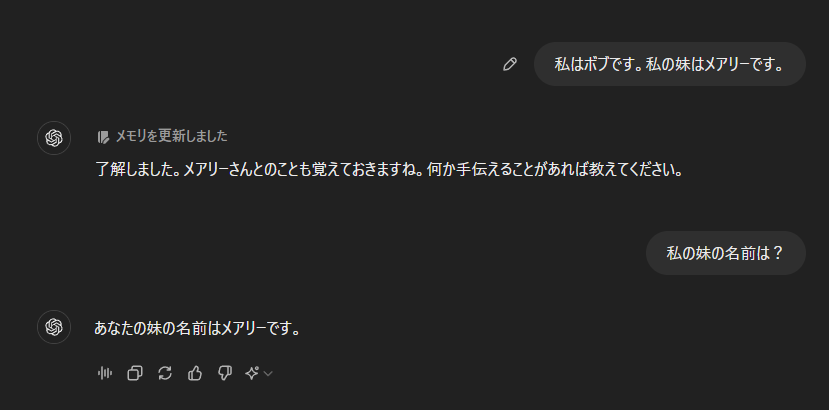
このように直接的に分かるものもあれば、
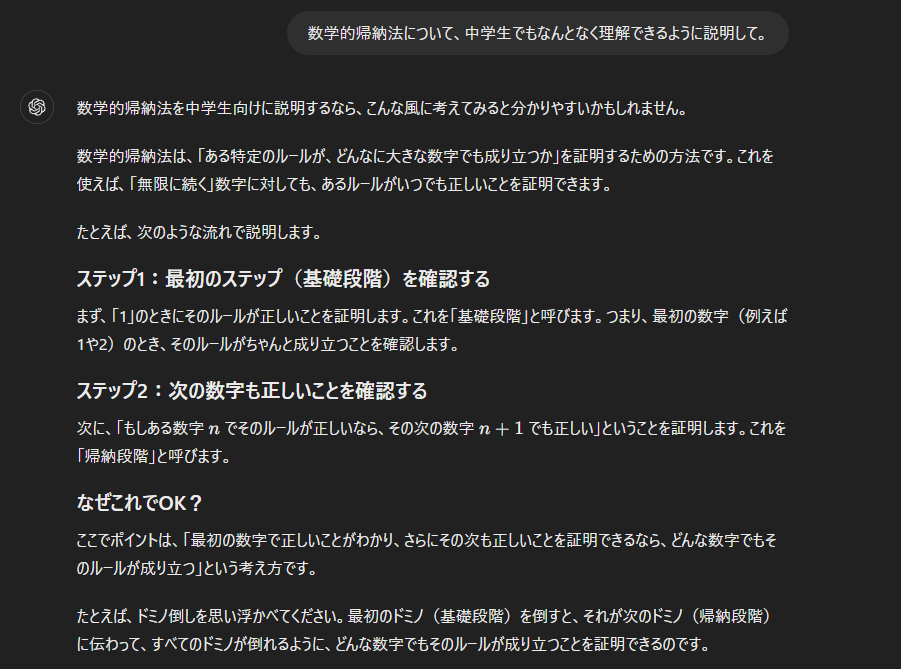
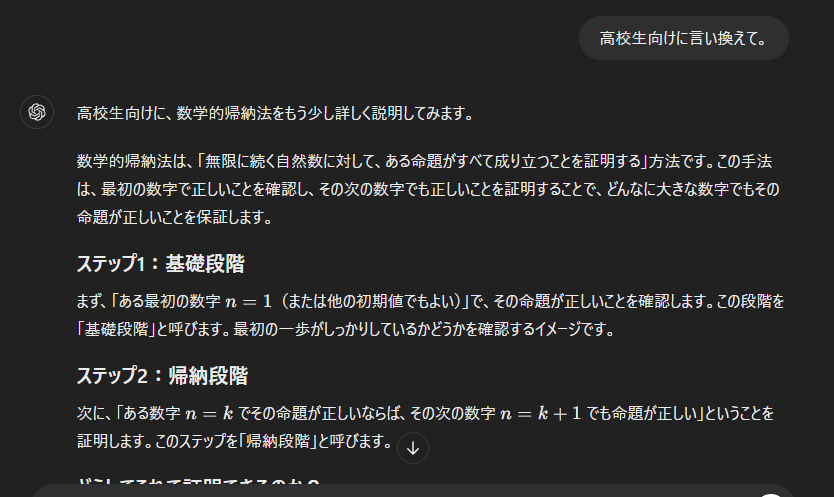
このように、何を言い換えるのか特に指定しなくても、前の文節から数学的帰納法について聞かれていると理解しているわけです。
ところで、以下のような場合はどうでしょうか。
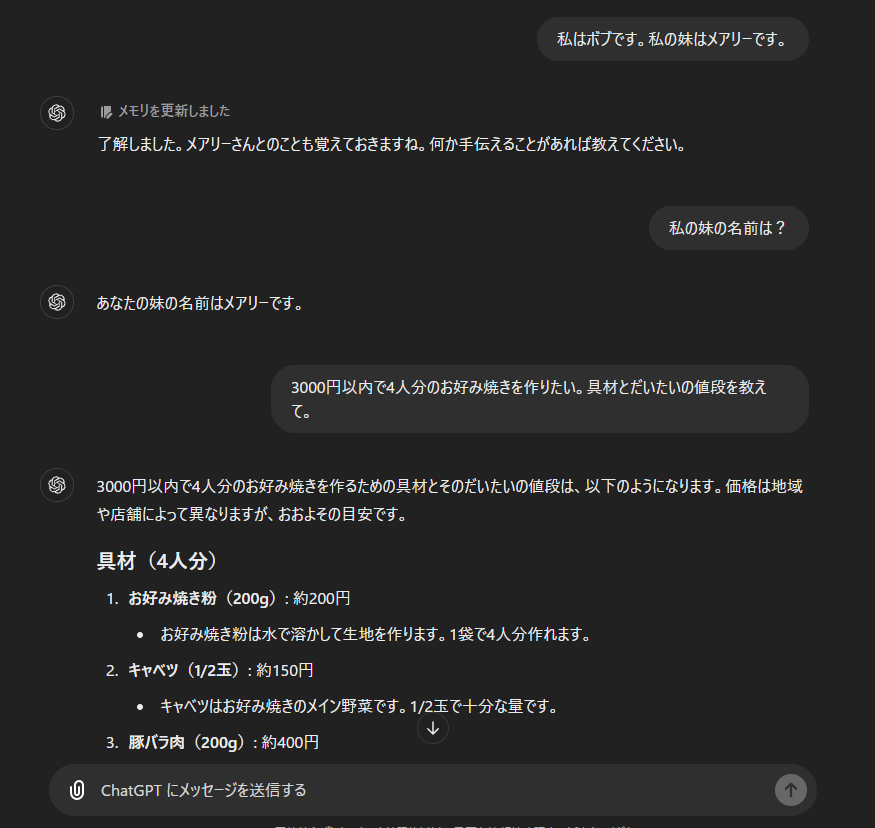
全く新しいトピックを聞いていますので、特に前の会話を参照する必要はないですね。ところが、このような場合でも生成AIは前の会話を全て記憶しています。
もちろん使用する上で問題はないのですが、問題はトークン数です。
トークン数とはChatGPTやCluadeのようなクローズドモデルのAIを使用する際に発生するコストのことです。
ブラウザ版で利用する場合は、トークン数を一定以上消費してしまうと使用制限がかかってしまったり、
API利用する場合はトークン数に比例して費用が発生します。
会話履歴を参照していると一回の会話あたりにかかるトークン数がどんどん増えていってしまいます。
このため、前の例のような場合は新しい会話を始めたほうが良いと思います。
会話履歴参照でトークン数が増加するかテストしてみた
ChainlitというPythonライブラリを用いて、トークン数計測テストをしてみました。
また、LangChainのMemory機能を使って、API利用でも会話履歴を保存する設定にしてみます。
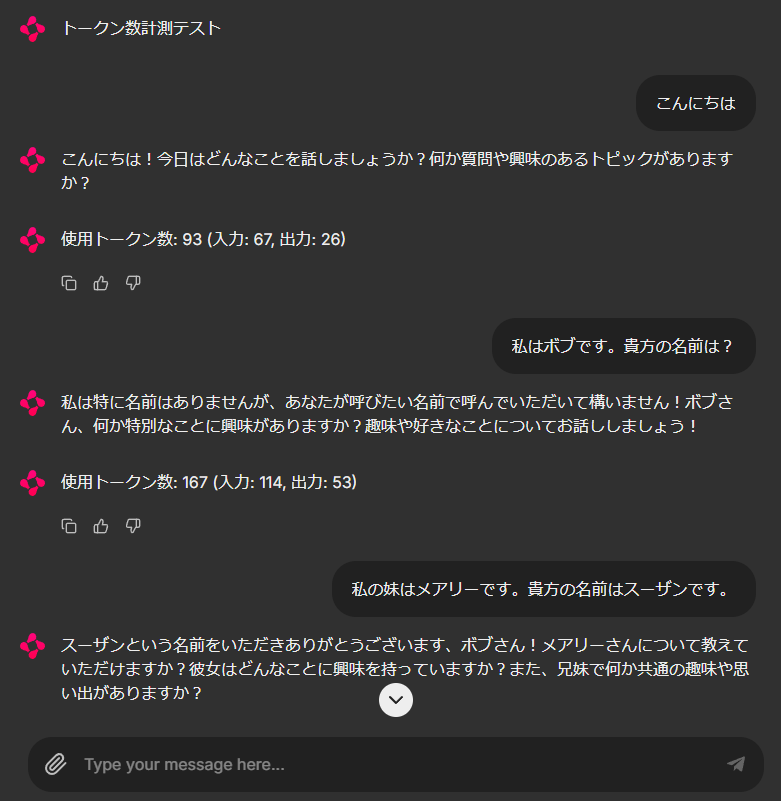
上の画像のように、1回の会話毎に使用したトークン数を表示させます。

LLMが会話履歴をしっかり記憶して回答を生成できているのが分かります。
注目していただきたいのは入力トークン数で、先ほどから入力文は「メアリーの兄は誰?」などとても
短いにもかかわらず、会話毎に増加していっているのが分かります。
API利用ですので、会話履歴が増えるほど、1会話あたりの費用が増加しています。
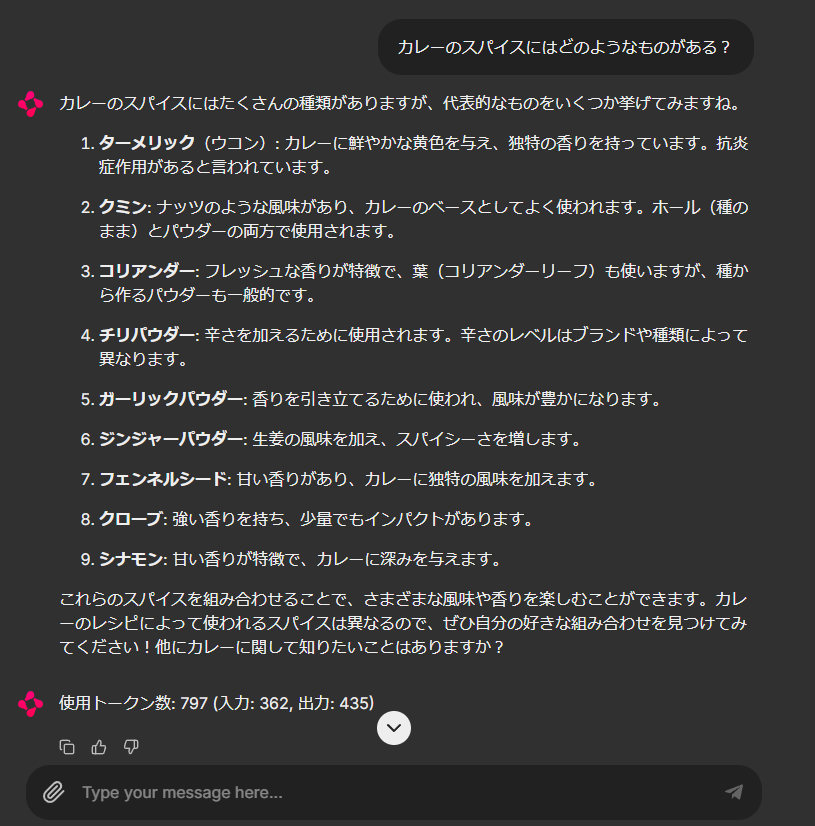
このときに、上記のような前の会話履歴を参照する必要のない質問をしてしまうと、無駄にコストがかかってしまうわけです。新しいトピックの場合は、新しい会話を開くように気を付けましょう。
ここまでお読みいただきありがとうございました。